|
|
 |
|
|
- [2024.04] I am delighted to announce that our paper Total-Decom has been selected as the highlight poster (acceptance rate 2.8%), and EscherNet has been chosen for an oral presentation (acceptance rate 0.78%) for CVPR 2024.
- [2024.02] We have three papers accepted to the CVPR 2024, one as the first author. All code and demos will be open source.
- [2024.02] We have released the code and demos about the EscherNet, which is a multi-view conditioned diffusion model for generative view synthesis. Welcome to check!
- [2023.12] We have released the demos about the SC-GS, which is a controllable dynamic gaussian. Welcome to check!
- [2023.07] Three papers accepted to ICCV2023, one as the first author.
- [2023.03] One paper accepted to CVPR2023.
- [2023.01] One paper accepted to ICRA2023.
|
|
|
 |
Highlights (acceptance rate 2.8%) Indoor scenes consist of complex compositions of objects and backgrounds. Our proposed method, Total-Decom, (a) performs 3D reconstruction from posed multiview images, (b) decomposes the reconstructed mesh to generate high-quality meshes for individual objects and backgrounds with minimal human annotations. This approach facilitates such applications as (c) object re-texturing and (d) scene reconfiguration. |
 |
Oral (acceptance rate 0.78%) EscherNet is a multi-view conditioned diffusion model for view synthesis. EscherNet learns implicit and generative 3D representations coupled with the camera positional encoding (CaPE), allowing continuous relative camera control between an arbitrary number of reference and target views. |
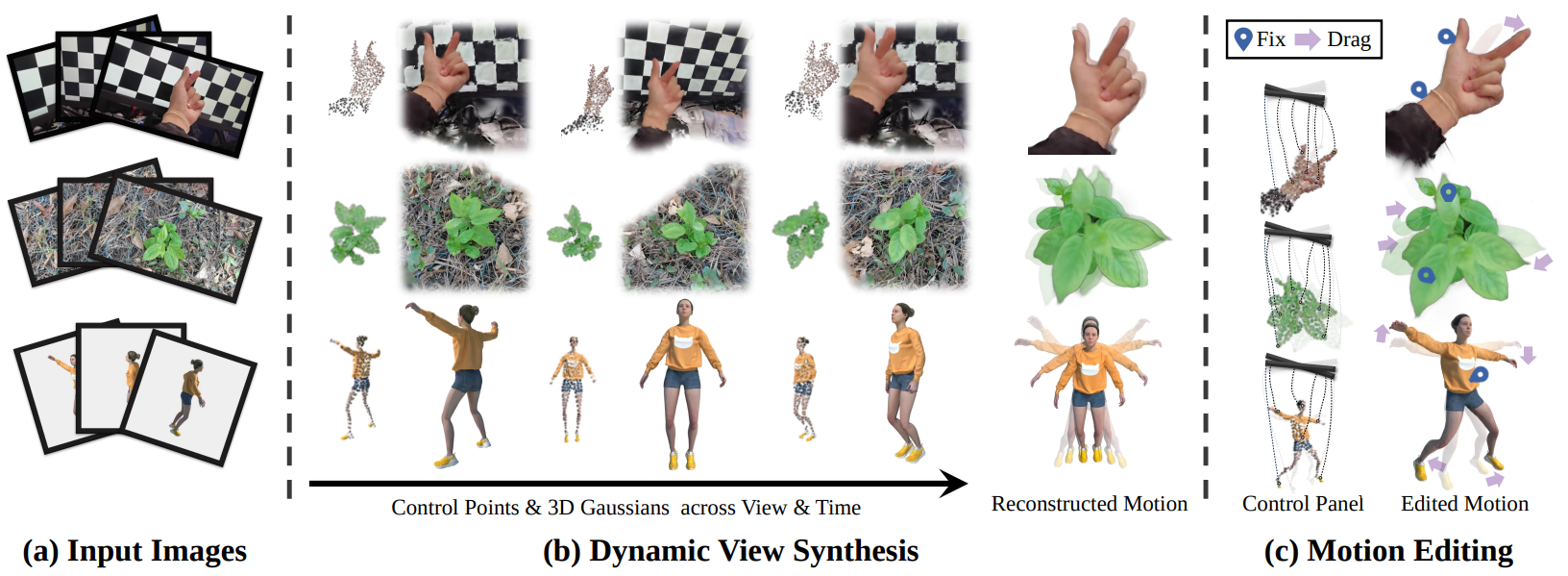 |
We propose a new representation that explicitly decomposes the motion and appearance of dynamic scenes into sparse control points and dense Gaussians, respectively. Our key idea is to use sparse control points, significantly fewer in number than the Gaussians, to learn compact 6 DoF transformation bases, which can be locally interpolated through learned interpolation weights to yield the motion field of 3D Gaussians. Please visit project page for more demos. |
 |
We have analyzed the constraints present in current neural scene representation techniques with geometry priors, and have identified issues in their ability to reconstruct detailed structures due to a biased optimization towards high color intensities and the complex SDF distribution. As a result, we have developed a feature rendering scheme that balances color regions and have implemented a hybrid representation to address the limitations of the SDF distribution. |
 |
We have presented RICO, a novel approach for compositional reconstruction in indoor scenes. Our key motivation is to regularize the unobservable regions for the objects with partial observations in indoor scenes. We exploit the geometry smoothness for the occluded background, and then adopt the improved background as the prior to regularize the objects’ geometry. |
 |
We propose a novel decomposition synthesis-composition framework called Speech2Lip for high-fidelity talking head video synthesis, which disentangles speech-sensitive and speech-insensitive motions/appearances. |
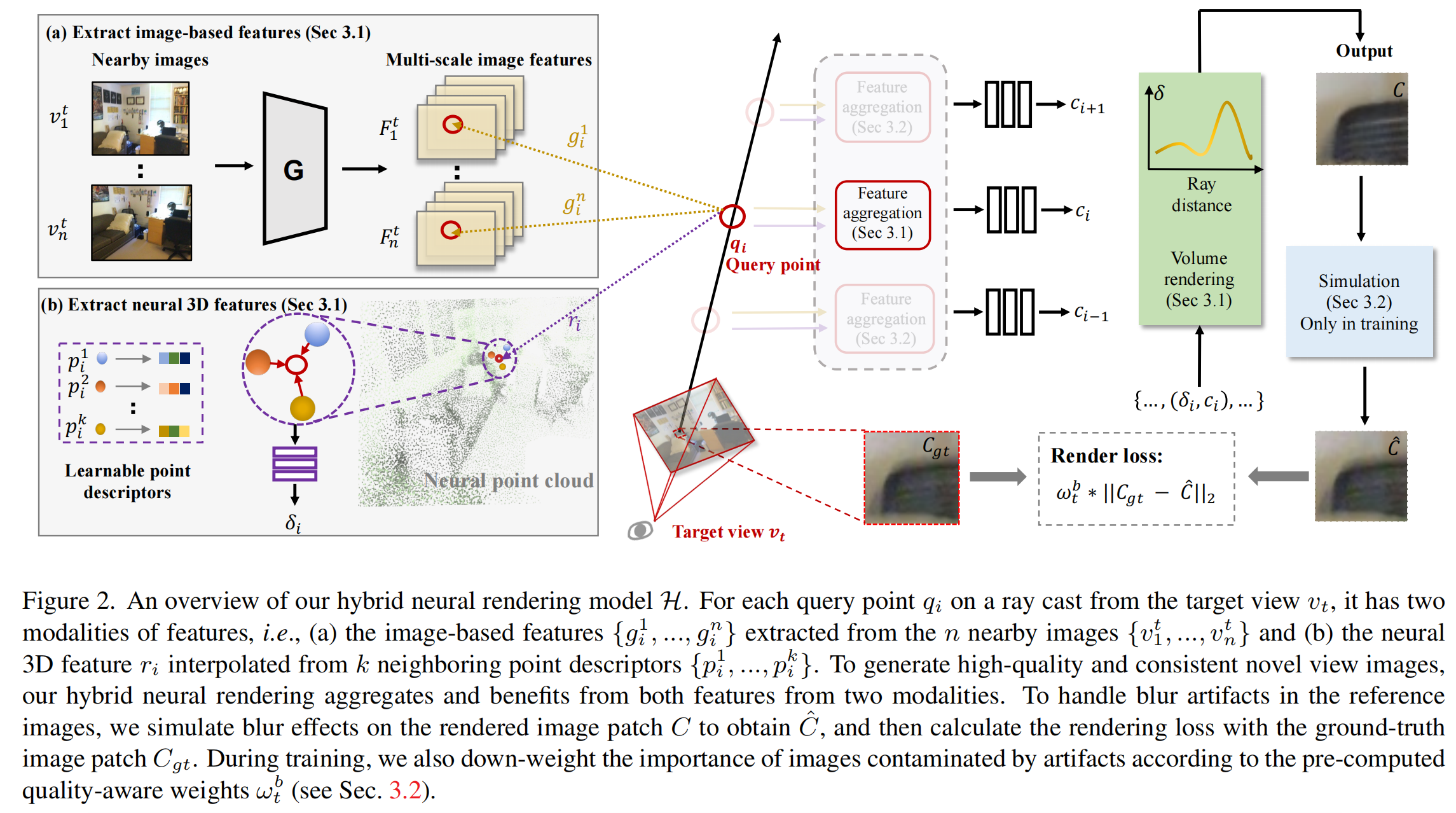 |
We develop a hybrid neural rendering model that makes image-based representation and neural 3D representation join forces to render high-quality and view-consistent images. |
 |
We propose a new method that uses sparse LiDAR point clouds and rough odometry to reconstruct fine-grained implicit occupancy field efficiently within a few minutes. We introduce a new loss function that supervises directly in 3D space without 2D rendering, avoiding information loss. |
 |
Based on theoretical and empirical evidence, we present HR-Depth, for high-resolution self-supervised monocular depth estimation. |
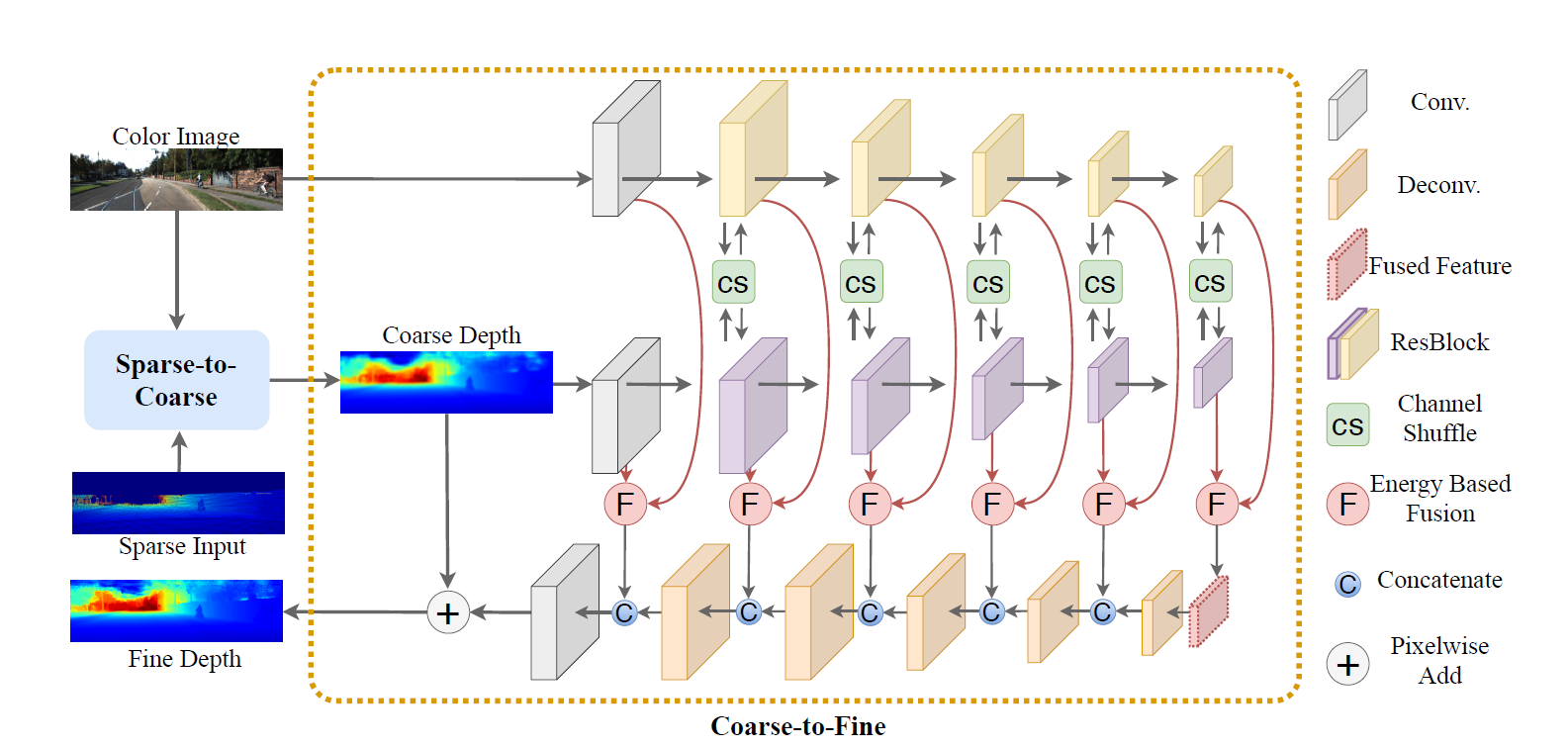 |
We propose a novel end-to-end residual learning framework, which formulates the depth completion as a tow-stage learning task. |
|
|
 |
Our team built two fully automatic robots, including machinery, circuit, control and algorithm. I was responsible for visual servo, target detection, target localization and decision-making of robots. |
 |
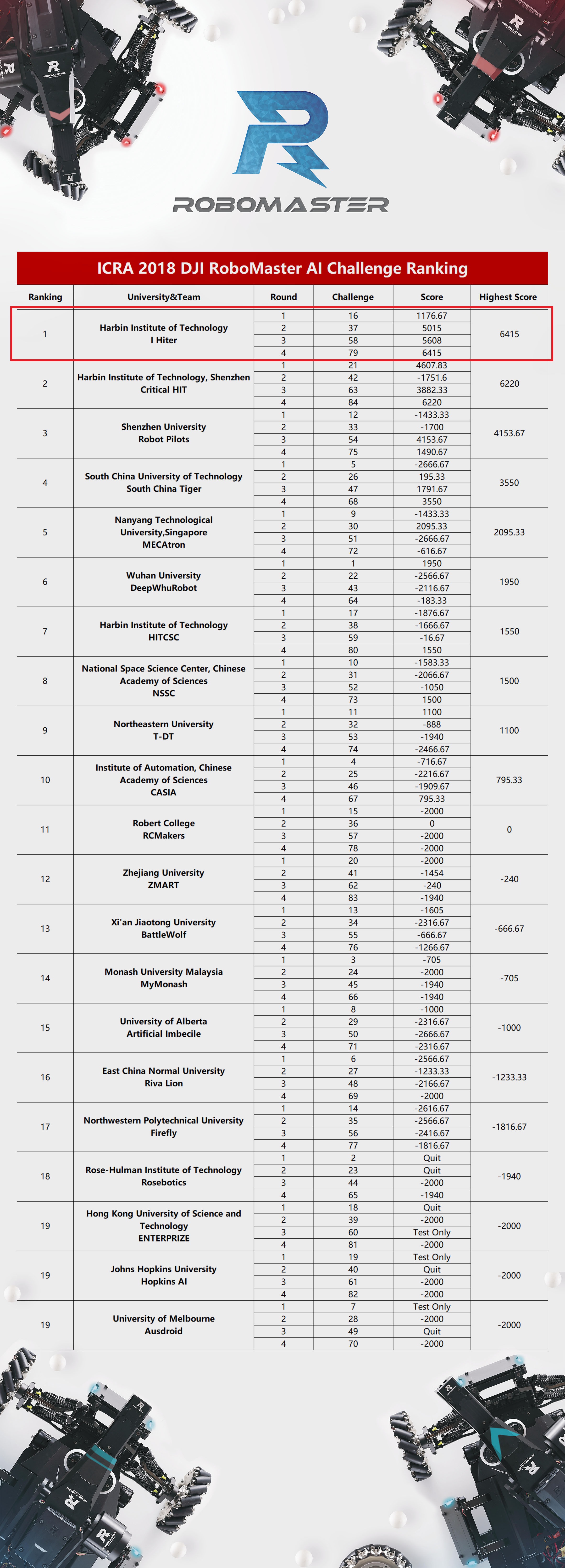
Our team built more than 10 complex automatic or semi-automatic robots every year. In 2017, I was mainly responsible for building and manipulating Engineering Robot. In 2018, I was responsible for visual servo, which involves computer vision and machine learning. In 2019, I became the leader of computer vision group and the coach of our team. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
Apr. 2022, Hong Kong PhD Fellowship Scheme - Research Grants Council (RGC) of Hong Kong Nov. 2019, Academic scholarship - Zhejiang University Jun. 2019, Outstanding Graduate - Harbin Institute of Technology Jun. 2019, Top 100 excellent graduation thesis - Harbin Institute of Technology Jan. 2019, Top 10 College Student in Harbin Institute of Technology - Harbin Institute of Technology Mar. 2018, Outstanding student in Hei Longjiang Province - Harbin Institute of Technology Oct. 2017, SMC Scholarship - Harbin Institute of Technology Oct. 2016, National Scholarship - Harbin Institute of Technology |
|
Skills: Python / C / C ++ / Matlab, PyTorch, Linux, ROS, OpenCV |
|
|
Last update: 2024.04.06. Thanks. |