Scale-shift drift
Naive streaming inference makes each frame live in a slightly different coordinate system, creating layering breaks and positional jitter.
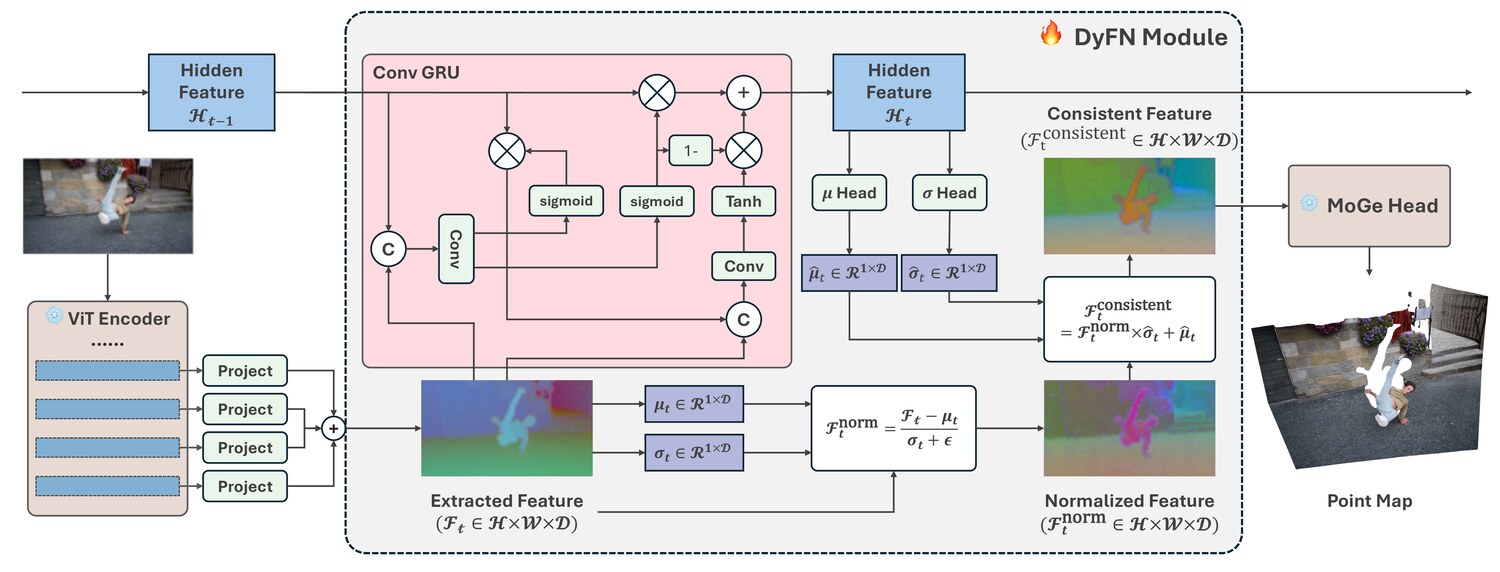
A lightweight recurrent stabilizer that turns image geometry foundation models into coherent streaming video models.

Modern monocular geometry and depth foundation models are accurate on individual images, but when they are applied frame-by-frame to video streams, their predictions drift in scale and shift. DyFN targets that drift directly, preserving the frozen model's single-image accuracy while stabilizing geometry over time.
Naive streaming inference makes each frame live in a slightly different coordinate system, creating layering breaks and positional jitter.
The paper modulates latent mean and variance and observes large scale-shift changes while relative geometry remains accurate after alignment.
DyFN freezes the pretrained encoder and decoder, fine-tuning only a lightweight recurrent module. The final results achieves SOTA on the video depth estimation benchmark.
DyFN starts from a simple empirical question: do streaming artifacts come from bad per-frame geometry, or from a drifting coordinate system across frames? The paper tests this with MoGe by fusing video-frame predictions under two alignment settings.
When each frame is independently aligned to metric scale using its own affine scale and shift, the reconstructed geometry is accurate and coherent. When the full sequence must share one scale and shift, the same model produces visible non-rigid warping and drift. This isolates the failure mode: the geometry is present, but its global scale and offset fluctuate over time.
The study tests whether latent feature statistics control the scale-shift drift. We modulate the encoder feature variance and mean with α and β, then decode the result and inspect how the point cloud changes across the sweep.



Indoor scale-shift sweep
5 x 5 AbsRel color mapCompare per-frame affine alignment against one sequence-wide alignment to expose whether drift comes from global scale and shift.
Normalize encoder features, rescale their mean and variance, and decode with the frozen MGE decoder.
Because mean and variance govern scale-shift behavior, DyFN learns temporally stable statistics for the streaming feature sequence.
DyFN stabilizes the feature statistics that the empirical study identifies as the source of scale-shift drift. The detailed module structure is shown below.
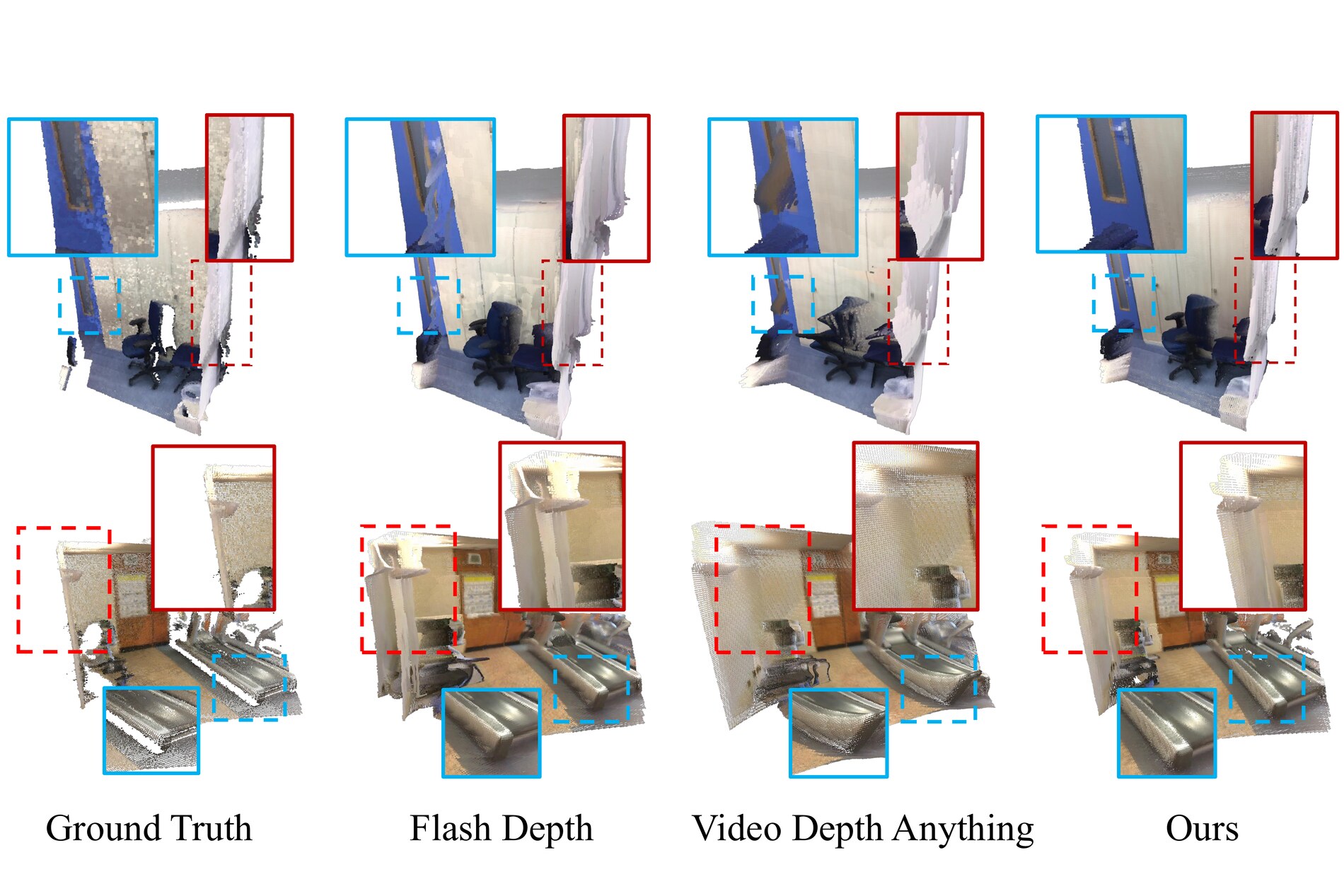
Across Sintel, ScanNet, KITTI, and Bonn, DyFN improves video depth stability while preserving the single-frame quality of its base model. The paper compares against six categories of depth and geometry methods under a sequence-level alignment protocol for video stability.
| Method | Sintel (50 frames) | ScanNet (90 frames) | KITTI (110 frames) | Bonn (110 frames) | ||||
|---|---|---|---|---|---|---|---|---|
| AbsRel ↓ | \(\delta_1 < 1.25\) ↑ | AbsRel ↓ | \(\delta_1 < 1.25\) ↑ | AbsRel ↓ | \(\delta_1 < 1.25\) ↑ | AbsRel ↓ | \(\delta_1 < 1.25\) ↑ | |
| Marigold | 0.532 | 51.5 | 0.166 | 76.9 | 0.149 | 79.6 | 0.091 | 93.1 |
| DA V1 | 0.325 | 56.4 | 0.130 | 83.8 | 0.142 | 80.3 | 0.078 | 93.9 |
| DA V2 | 0.367 | 55.4 | 0.135 | 82.2 | 0.140 | 80.4 | 0.106 | 92.1 |
| MoGe v1 | 0.216 | 65.3 | 0.117 | 84.7 | 0.076 | 96.0 | 0.074 | 95.5 |
| DepthPro | 0.319 | 52.0 | (0.088) | (92.7) | (0.088) | (92.2) | (0.063) | (96.6) |
| MoGe v2 | 0.214 | 69.5 | (0.110) | (88.2) | (0.183) | (58.8) | (0.049) | (98.0) |
| VGGT | 0.287 | 66.1 | 0.031 | 98.5 | 0.070 | 96.5 | 0.055 | 97.1 |
| Monst3R | 0.335 | 58.5 | 0.123 | 83.2 | 0.104 | 89.5 | 0.063 | 96.4 |
| CUT3R | 0.421 | 47.9 | 0.097 | 88.7 | 0.118 | 88.1 | 0.078 | 93.7 |
| TTT3R | 0.404 | 50.0 | 0.114 | 87.7 | 0.113 | 90.4 | 0.068 | 95.4 |
| DepthCrafter | 0.270 | 69.7 | 0.123 | 85.6 | 0.104 | 89.6 | 0.071 | 97.2 |
| VDA | 0.300 | 63.3 | 0.075 | 95.4 | 0.079 | 95.0 | 0.051 | 98.1 |
| FlashDepth | 0.265 | 64.2 | 0.101 | 90.3 | 0.103 | 89.5 | 0.053 | 98.0 |
| Ours | 0.180 | 73.0 | 0.073 | 96.6 | 0.062 | 97.3 | 0.044 | 98.4 |
The demo shows DyFN on a continuous stream and reconstructed geometry.
Streaming reconstruction demo
The dominant failure is scale-shift drift caused by latent feature statistic fluctuation.
DyFN adapts strong image geometry models to streams without sacrificing their single-frame accuracy.
The recurrent module supports online streaming and is small enough to fine-tune efficiently.
Please cite the paper if you find the project useful.
@inproceedings{lyu2026streamingdepth,
title={Stabilizing Streaming Video Geometry via Dynamic Feature Normalization},
author={Lyu, Xiaoyang and Liu, Muxin and Wu, Xiaoshan and Wang, Ruicheng and Huang, Yi-Hua and Sun, Yang-Tian and Shi, Shaoshuai and Qi, Xiaojuan},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2026}
}